|
I am a Senior Research Scientist at DeepMind in London. I did my PhD in Physics at Princeton University, advised by David Schwab and Bill Bialek, and funded by a Hertz Fellowship and DOE Computational Science Graduate Fellowship. Before that, I did a master's at the University of Cambridge with Mate Lengyel as a Churchill Scholar and studied physics and mathematics at the University of Southern California, where I worked with Bartlett Mel and Paolo Zanardi and had a blog. Throughout my studies, I interned at DeepMind with Matt Botvinick, Stanford University with Kwabena Boahen, the Institute for Quantum Computing with Andrew Childs, and Spotify NYC with their machine learning team. I also enjoy a good puzzle. |

|
|
I'm broadly interested in reinforcement and deep learning. Lately, I've been especially interested in the efficient training of agents that can meaningfully interact and collaborate with humans. My PhD thesis ("Optimization of MILES") focused on applications of the information bottleneck (IB) across supervised, unsupervised, and reinforcement learning, and definitely not on collecting airline miles. In past lives, I've also worked on quantum information theory and computational neuroscience. |
|
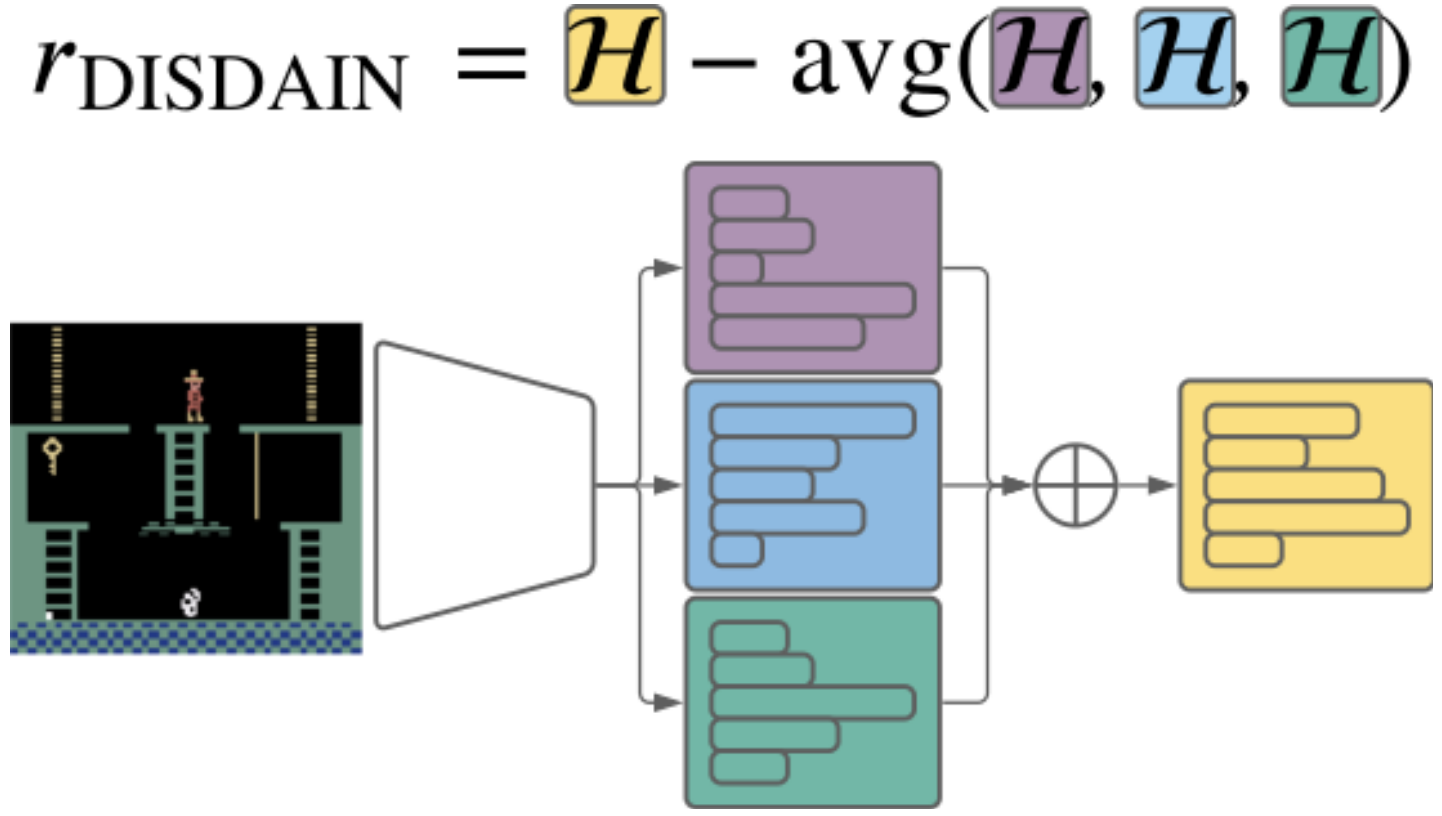
DJ Strouse*, Kate Baumli, David Warde-Farley, Vlad Mnih, Steven Hansen* International Conference on Learning Representations (ICLR), 2022 arxiv | openreview | github | tweet | show bibtex We highlight the inherent pessmism towards exploration in a popular family of variational unsupervised skill learning methods. To curb this pessimism, we propose an ensemble uncertainty based exploration bonus that we call discriminator disagreement intrinsic reward, or DISDAIN. We show that DISDAIN improves skill learning in both a gridworld and the Atari57 suite. Thus, we encourage researchers to treat pessimism with DISDAIN.
@inproceedings{strouse2022disdain, |
|
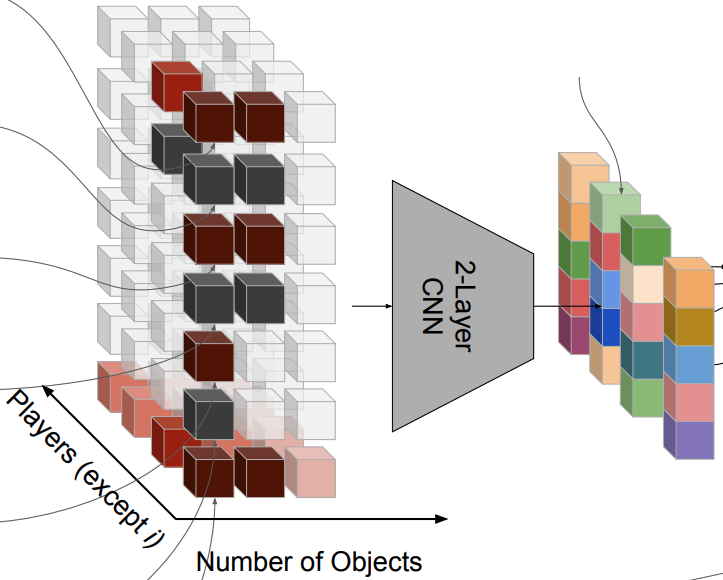
Andrea Tacchetti, DJ Strouse, Marta Garnelo, Thore Graepel, Yoram Bachrach ICLR Gamification and Multiagent Solutions Workshop, 2022 arxiv | openreview | show bibtex We present a deep learning approach to auction design that guarantees truthfulness (bidders are incentivized to be honest) and efficiency (whoever wants the item most gets it). We focus on social utility maximizing auctions, where the goal is to achieve the former constraints while placing as little economic burden on the bidders as possible.
@inproceedings{tacchetti2022auctioncnn, |
|
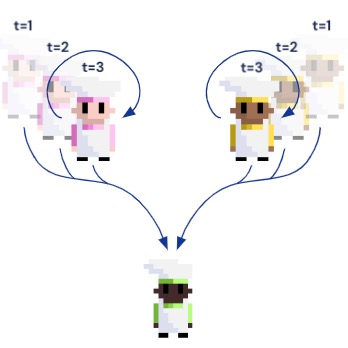
DJ Strouse*, Kevin R. McKee, Matt Botvinick, Edward Hughes, Richard Everett* Neural Information Processing Systems (NeurIPS), 2021 arxiv | neurips | openreview | tweet | alignment newsletter | show bibtex We introduce Fictitious Co-Play (FCP), a simple and intuitive training method for producing agents capable of zero-shot coordination with humans in Overcooked. FCP works by training an agent as the best response to a frozen pool of self-play agents and their past checkpoints. Notably, FCP exhibits robust generalization to humans, despite not using any human data during training.
@inproceedings{strouse2021fcp, |
|
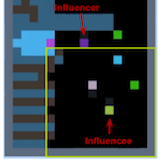
Natasha Jaques, Angeliki Lazaridou, Edward Hughes, Caglar Gulcehre, Pedro A. Ortega, DJ Strouse, Joel Z. Leibo, Nando de Freitas International Conference on Machine Learning (ICML), 2019 arxiv | icml | openreview | show bibtex We reward agents for influencing the actions of other agents, and show that this gives rise to better cooperation and more meaningful emergent communication protocols.
@inproceedings{jaques2019influence, |
|
DJ Strouse, David Schwab Neural Computation (NECO), 2019 pdf | neco | arxiv | code | show bibtex We show how to use the (deterministic) information bottleneck to perform geometric clustering, introducing a novel information-theoretic model selection criterion. We show how this relates to and generalizes k-means and gaussian mixture models (GMMs).
@article{strouse2019clustering, |

|
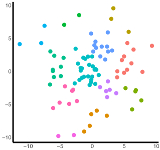
Anirudh Goyal, Riashat Islam, DJ Strouse, Zafarali Ahmed, Hugo Larochelle, Matt Botvinick, Sergey Levine, Yoshua Bengio International Conference on Learning Representations (ICLR), 2019 arxiv | openreview | show bibtex We train agents in multi-goal environments with an information bottleneck between their goal and policy. This encourages agents to develop useful "habits" that generalize across goals. We identify the states where agents must deviate from their habits to solve a task as "decision states" and show that they are useful targets for an exploration bonus.
@inproceedings{goyal2019infobot, |
|
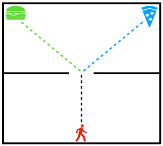
DJ Strouse, Max Kleiman-Weiner, Josh Tenenbaum, Matt Botvinick, David Schwab Neural Information Processing Systems (NIPS), 2018 arxiv | nips | code | show bibtex We train agents to cooperate / compete by regularizing the reward-relevant information they share with other agents, enabling agents trained alone to nevertheless perform well in a multi-agent setting.
@inproceedings{strouse2018intentions, |
|
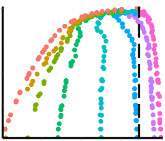
DJ Strouse, David Schwab Neural Computation (NECO), 2017 & Uncertainty in Artificial Intelligence (UAI), 2016 pdf | arxiv | code | uai | neco | show bibtex We introduce the deterministic information bottleneck (DIB), an alternative formulation of the information bottleneck that uses entropy instead of mutual information to measure compression. This results in a hard clustering algorithm with a built-in preference for using fewer clusters.
@article{strouse2017dib, |
|
| |
|
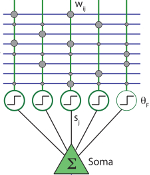
Xundong Wu, Gabriel Mel, DJ Strouse, Bartlett Mel PLoS Computational Biology, 2019 plos We study the optimal conditions for online recognition memory in a biologically-inspired neural network with "dendrite-aware" learning rules. |
|
DJ Strouse, Balazs Ujfalussy, Mate Lengyel Computational and Systems Neuroscience (Cosyne), 2012 & 2013 2012 poster & abstract | 2013 poster & abstract | master's thesis | why We fit neural network models to single neuron data to understand the computational role of dendrites in integrating their synaptic input. |
|
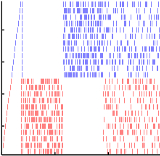
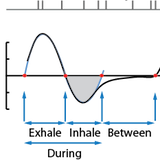
DJ Strouse, Jakob Macke, Roman Shusterman, Dima Rinberg, Elad Schneidman Sensory Coding & the Natural Environments (SCNE), 2012 abstract | poster We study the olfactory neural code in mice and find that much of the information about the stimulus is only decodable when interpreting neural activity relative to the sniff phase, providing evidence for the importance of considering sensory sampling behavior when interpreting neural codes. |
|
| |
|
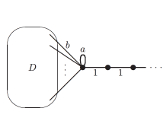
Andrew Childs, DJ Strouse Journal of Mathematical Physics (JMP), 2011 arxiv | jmp | talk We prove an analog of a classic result in quantum scattering theory for the setting of scattering on graphs. The goal is to provide additional tools for designing quantum algorithms in this setting. |
| |